
Freedom and privacy with zero-knowledge proofs
Zero-knowledge proofs allow you to decentralize execution, which gives you more freedom and privacy and makes blockchains more efficient.

We recently published a simple introduction to zero-knowledge proofs. In it, we covered the « obvious » advantages of ZK technology and its uniqueness.
There’s one thing that we wanted to cover in more detail, so we decided to dedicate an entire article to it. Today, we’re bringing to light one salient advantage of zero-knowledge: choosing where you execute your code. You have decentralization and privacy. You can do what you want and do it wherever you want − people have the guarantee that you’re trustworthy.
Understanding zero-knowledge proofs in practice
In this section, we’ll cover why and how computation execution happens where you want it to.
Let’s take the example of a User who wants to prove a conclusion to an Entity. Without zero knowledge, the User will give their information to the Entity, which will process it and make its own conclusion.
For instance, let’s suppose I (the User) want to prove to a French whiskey-selling website (the Entity) that I am over the age of 18 (the conclusion). I’ll send something like a photo of my ID card (the data), and the website will process that photo, check the date, and conclude from it that I am indeed old enough to buy a bottle.
The Entity can trust the conclusion because they got to the conclusion themself.
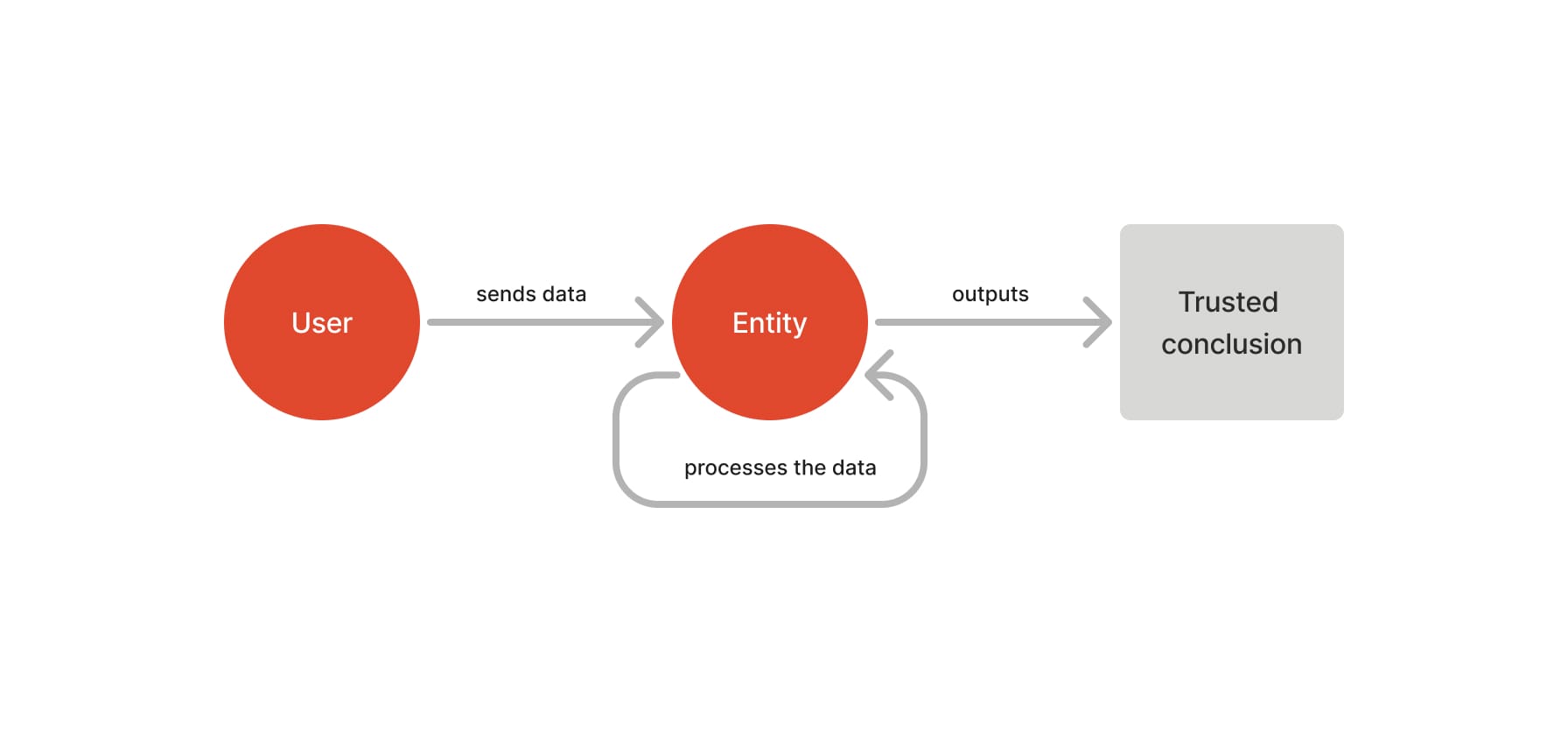
Zero-knowledge proofs change that. Their goal is to remove the step where the data is processed while maintaining trust in the validity of the conclusion.
With zero-knowledge proofs, I don’t need to send my entire ID card to the Entity anymore. I can use a protocol that has been defined and accepted by everyone beforehand and guarantee that my conclusion is proper.
If you want to check out an actual project that does this (it requires an iPhone app), check out the amazingly named CornHub, a demo built by Ocelot and the zkPassport team at zkHack Krakow.

With this flow, the French whiskey-selling website receives proof that I am over 18 while never having had access to my identity. But why should the Entity believe this proof? How can the Entity be sure that they’ve received data they can trust?
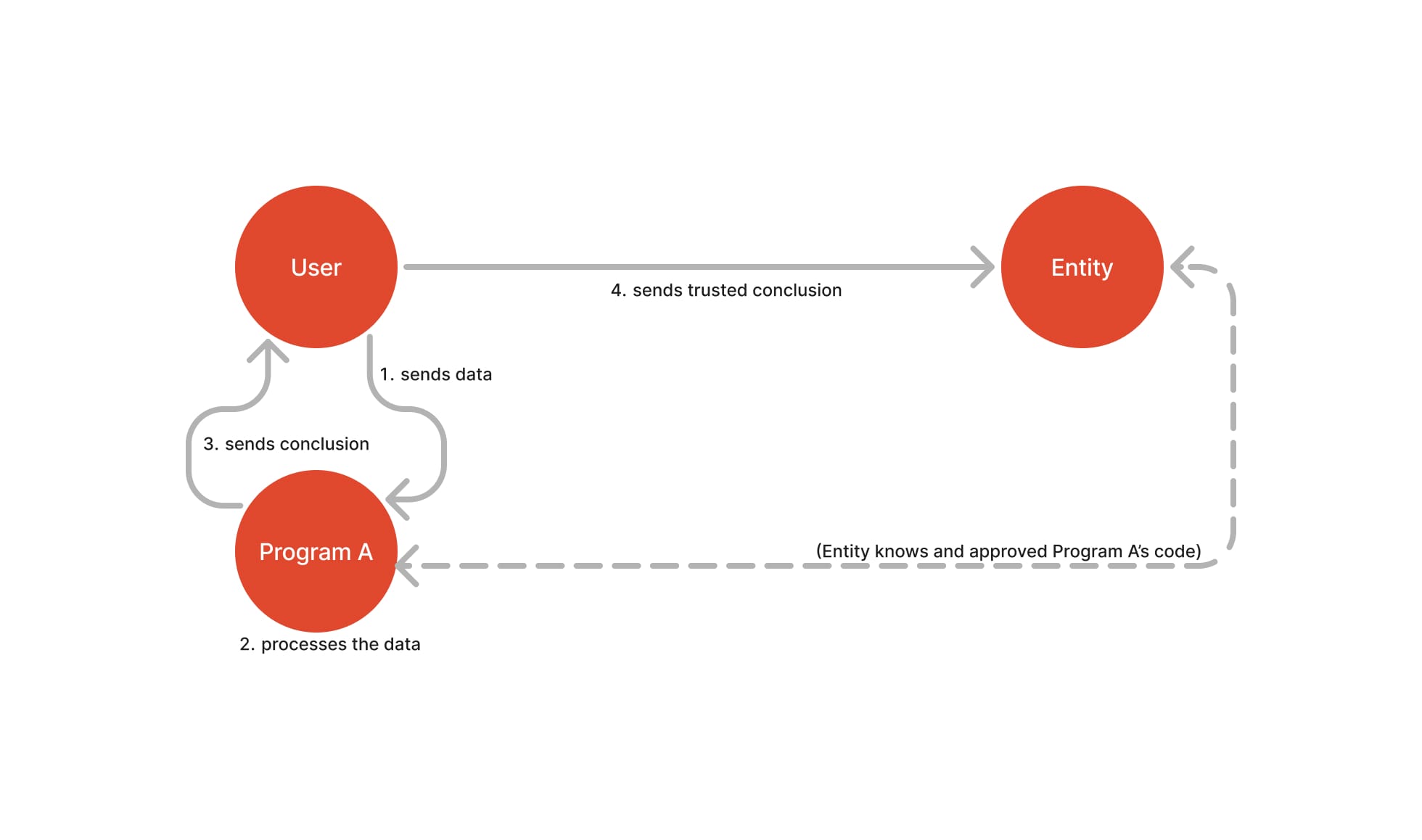
Well… my previous graph was a lie.
As the User processes the data, I really can’t do « whatever I want ». Before I got to manipulate the data, the Entity publicly said: « I only accept conclusions that have been processed following Program A ». That’s where the magic of ZKP lies, although it might not be obvious yet. If I tamper with the program or use Program B, the Entity will know, and it won’t trust me.
A more accurate graphical representation would, therefore, look more like this:
Executing wherever you want guarantees true privacy
But what does this all mean?
Letting the User decide on where to execute computation is a great privacy guarantee.
The User doesn’t need to send the data anymore. They don’t need to trust the Entity to keep their data secure, and the Entity doesn’t need a whole privacy management framework anymore. There is no data for the Entity to protect in the first place anymore.
And even more importantly, by letting the User choose where their data will live, ZKP also allows the User to decide where the data will be processed.
I can now:
- take a photo of my passport with my phone;
- generate proof that I am over 18 directly from my phone, for instance, through the European Digital Identity Framework;
- only send that proof to the Entity.
I don’t need my whiskey-selling website to know my gender, my middle name or to see what my signature looks like. It’s all information that’s on my passport and was never relevant in the first place, but that the website needed when a photo of my passport was the only way to prove my age.
With zero-knowledge proofs, I benefit from complete privacy, and the Entity still knows that my data can be trusted. That’s already great on its own − and we haven’t even mentioned freedom yet.
Executing whatever you want allows for reusing data
What if I decided to opt for an American whiskey retailer and needed to prove that I am over 21 instead of 18?
As I am both executing the program and owning the data, I can actually run whichever program I want. Hence, I will prove whatever I want about my data.
But then, how does the Entity know it is verifying proof of age above 21 and not for age above 18?
To verify a proof generated by Program A, all the Entity needs to know, outside of the conclusion itself, is (more or less) the program's code. As long as the Entity knows (and trusts) a Program, it can accept a proof coming from it.
The Entity can understand the conclusion (they know what the code does; for example, they know that « yes » means « yes, this person’s data says they’re over 21 »). They can verify that the proof is legitimate by checking that the code has not been tampered with and confirming that the right program generated it.
Whatever the Program and whatever the Entity, in the end, I own my data. I can run any Program I want over it. In other words, I am free. I can use the photo of my ID card to prove that I am over 18 on the whiskey-selling website, or I can use that photo to prove that I am French and can represent my country at the Just Dance Olympics. All I need is a Program that the Entity knows and will accept.
So not only do I have privacy, but I can also reuse my data with full flexibility, saving time and storage and giving me maximum freedom.
It allows me to disclose information selectively: I can choose to prove that I’m over 18, to show how old I am, or to share my exact age and birthday using a single program. I can also choose to share my nationality and my age. It’s not « share nothing » vs. « share everything » anymore: ZK allows for a level of nuance that was simply unimaginable before. It's selective disclosure of information backed by cryptography.
But wait… there’s more!
Decentralizing execution for blockchain efficiency
Being able to compute data wherever we want means decentralizing execution.
Ethereum is fully decentralized, but having every single member of the network redo the exact computation is vastly inefficient. ZKPs allow you to choose the correct execution environment for the job.
Uma Roy, CEO of Succinct Labs and Hylé business angel, highlighted that in a recent video.
Why ZK will be as important as blockchain, explained in < 2 minutes. pic.twitter.com/vo21ifGSdj
— Succinct (@SuccinctLabs) June 25, 2024
Computing wherever I want is an advantage not only for the User, as we’ve seen, but also for blockchains. Classic protocols imply that every node must recompute every transaction in a block. With zero-knowledge proofs, only one prover must do this computation. They can then provide proof that the computation went well, and the other nodes can just verify that proof. It saves an incredible amount of time − and, as a consequence, money. This is how validity rollups operate, allowing blockchains like Ethereum to scale.
That’s where ZKP brings so much scalability to decentralized systems. Not only do you get privacy and the basis for more trust, but you also can execute transactions off-chain and still prove their correct execution on-chain. That way, you benefit from higher speed while keeping the trustlessness guarantees of decentralized blockchains.
Zero-knowledge technology brings us the freedom to choose where we execute code. It allows us to benefit from maximum decentralization and privacy without ever damaging trust. With zero-knowledge proofs, you can do whatever you want, wherever you want. And then, you can submit proof for everyone else to trust you. It’s an open door to the future of decentralization and Trust Infrastructure.
This post's main author is Maximilien.