
Some like it proved: an architecture for provable apps, with Lancelot at zkSummit 12
Lancelot's talk at zkSummit 12 on what we think will be the future of dApps and smart contract development thanks to zero-knowledge proofs.

Our co-founder and CTO Lancelot was invited to speak at zkSummit 12 about provable apps and how Hylé enables them. Watch his talk, or read the transcript below!
I'm Lancelot, I'm co-founder and CTO of Hylé.
We're building a blockchain network targeting zkApps. What I'm going to be talking about is what we're doing, but it's also what we think will happen anyway.
I was previously working in the StarkNet ecosystem on an NFT protocol called briq; you might know some of that. This was my introduction to zero-knowledge technology and validity proofs and things like that.
What I'm going to be talking about is what we think will be the future of dApps and smart contract development thanks to zero-knowledge proofs and the impact this will have on applications and blockchains − because I'm talking about a blockchain context here.
Building the onchain game of 2030
Let's do a quick thought experiment.
Let's say it's 2030 and you want to write an onchain game. Let's quickly answer the question, why would you go onchain?
I usually stray away from answering that, but there's a few good reasons why you might want that:
- Maybe you want the censorship resistance.
- Maybe you want liquidity access.
- Maybe you want to use the blockchain as a distribution network.
- And a few other legitimate things, but these are the three main ones.
Your 2030 needs for an onchain game
So if you want to go onchain because it's 2030, you don't want to think about calldata size or gas costs and all that jazz.
You shouldn't have to think about that in 2030, and because you're making an onchain game, you want to have low latency. You want it to be in real-time, to feel like a game.
And because it's 2030, maybe somehow the metaverse is hype again, and you want people to own an NFT to be able to play your game or something.
But maybe you don't want them to have to show which NFT they're using, so you want privacy. And with privacy:
- you'll have to use zero-knowledge proofs.
- so you'll have a proof of concept of a game written in rust.
- so you'll want to use one of the zkVMs that you can run Rust on. There's a bunch of them, but because it's 2030, you can use SP2 or RISC One. I couldn't find a good wordplay for Nexus or Veda or Jolt or any other ones. Leave comments on the Youtube video if you find one.
So you're writing an application. How do you put it onchain?
Applications and rollups will become interchangeable
Our argument is that applications and rollups will become interchangeable. They will be the same thing. Rollups are apps, and apps are rollups.
In that model, blockchains are just state machines. You have a state; you send a transaction that operates a state transition to a new state. For roll-ups, just take that and apply ZK or validity proofs, depending on the context of that. Your transactions are just proof of a state transition.
So you have an initial state that's like the green blob below, let's say, and that's just a state commitment. It's an iceberg: it hides that most of the data is not necessarily stored by the chain, but it's there. You just have this commitment and all of your transactions are just state transitions.
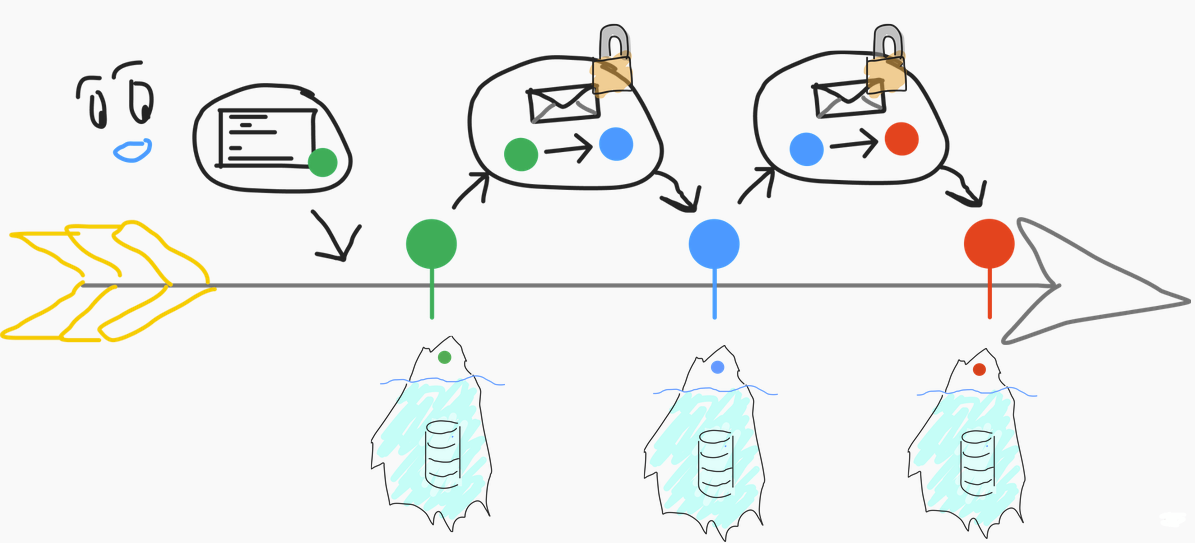
You go from the green state commitment to the blue state commitment to the red one.
And every time, there's an underlying database that's full of information that you don't really need to know about to confirm that the information is secure. That's because you have a zero-knowledge proof that there is a valid transition (according to your application) from the green blob to the blue blob to the red blob.
The key thing here is that those are ordered, and of course, you need to know some information about the program to be able to verify the proofs.
Depending on the system, the information could be a verification key, an image ID, or a bunch of other things!
How do you generate the proofs?
In 2030, you'll have a few options:
- You'll be able to do client-side proving. If you have access to the code of the application and you have access to the state of the application (because all of that is open source or widely distributed), you can just generate your proofs on your own computer because it's fast in 2030.
- You can do a small computation locally. Because the application you want to use is huge, even though it's fast, you want to send the rest to a centralized server, a B2B app that wants to do its own thing with it — to a SaaS, essentially.
- Or you'll want to leverage a proving market of some kind, where you just say « I have this thing, I want to generate a proof », and people do it for you, and you pay them for that.
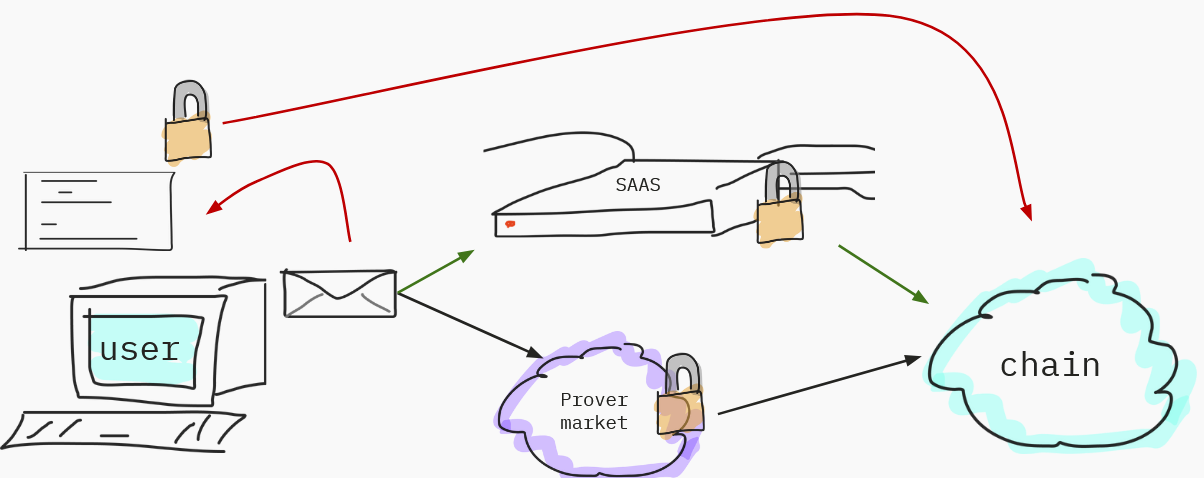
The proof is then sent to the chain, and we act on the state transition.
Indexing the information
Of course, once the information has been sent to the chain, you'll need to read and see it. For that, you'll need to index the information. Again, this is pretty straightforward.
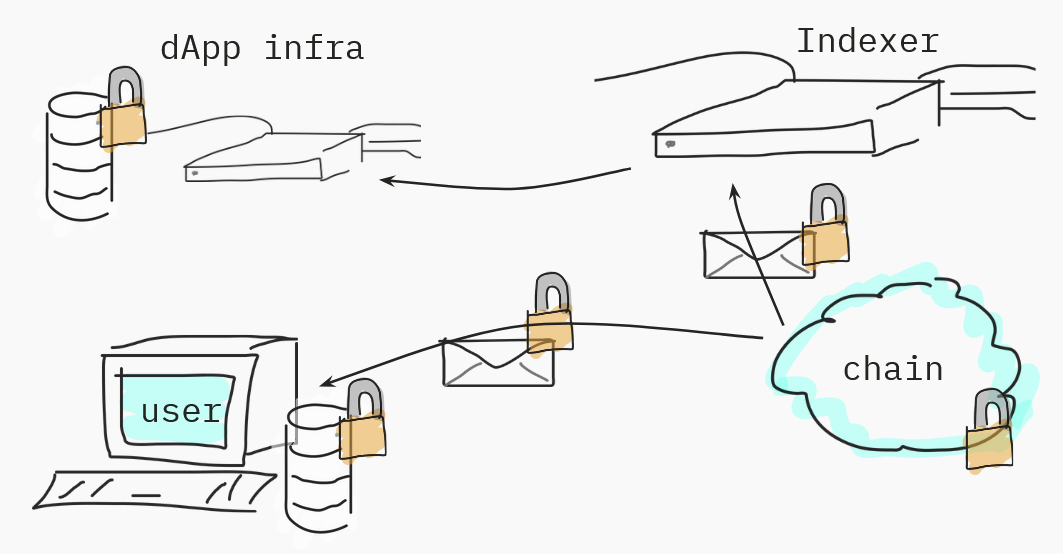
You have a bunch of options, but the two big ones are that either:
- You'll read the information yourself on the chain and reconstruct a local database of the app's information;
- You'll rely on the dApp server because it does its own indexing. It remains trustless because it can prove that the information it's showing you matches what's on the chain (with a Merkle inclusion proof, for example).
That's the whole property of the data integrity security provided by the chain.
Let's recap: Transactions are proof of state transitions, dApps are made of a verification key and a state root, users can prove client-side or use prover services, chains don't store data (but they guarantee data integrity), and indexing remains trustless.
Back to 2024: how do we get there?
It's 2024, and you want to write an onchain game. You'll have a reality check pretty quickly because there are a few problems:
- How do you do composable contract calls easily?
- Proving time and proving time latency are a big issue.
- Parallelization.
Composable contract calls
Let's get the simple one out of the way. To give an example here, you want people to need to own a CryptoPunk to be able to play Tetris. I'm not going to say why because there's really no reason to, but why not?
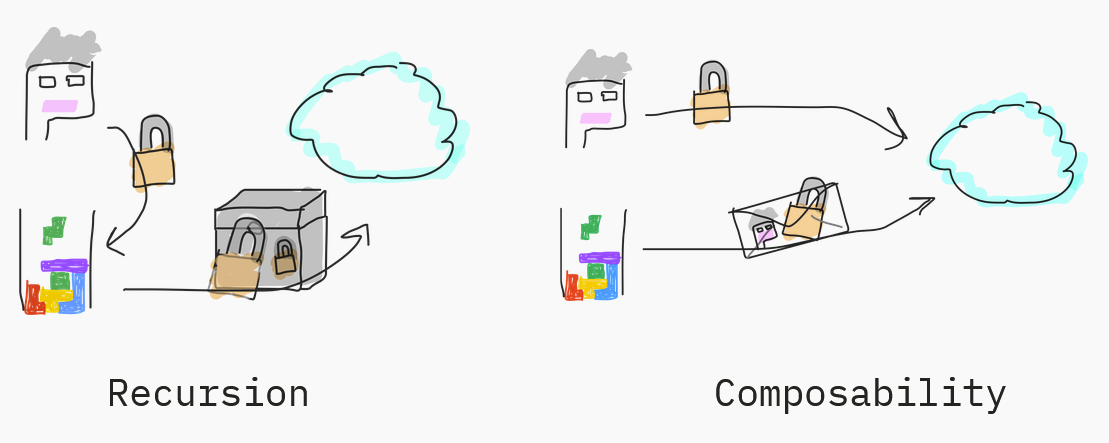
Recursion
If you are trying to do this conventionally, essentially, you'll have to embed the verification of the proof of ownership of a CryptoPunk within your Tetris game.
If you want to change that or the CryptoPunk contract, you'd have to update your Tetris contract because the two are embedded together; you can't change one and not the other.
Also, you need to be able to verify the proofs, so that implies that you're doing recursion, which can be slow and complicated.
Composability
What we think will happen in the future and what we're offering at Hylé is actual composability, where you have two separate proofs in your transaction:
- you have the proof that you own a CryptoPunk, which is doing its own thing.
- within the Tetris proof, you essentially say, « Protocol, please check that there is also proof for the ownership of a CryptoPunk », and the protocol will check that separately.
In a functional programming context, we push the side effects to the end of the computation and just verify that things seem to match at the end instead of doing it along the way in a more linear pattern.
So that's the easy thing.
Proving time and parallelization
Let's take another, slightly more realistic example: you have an auction. The auction ends at the red bar on the timeline below.
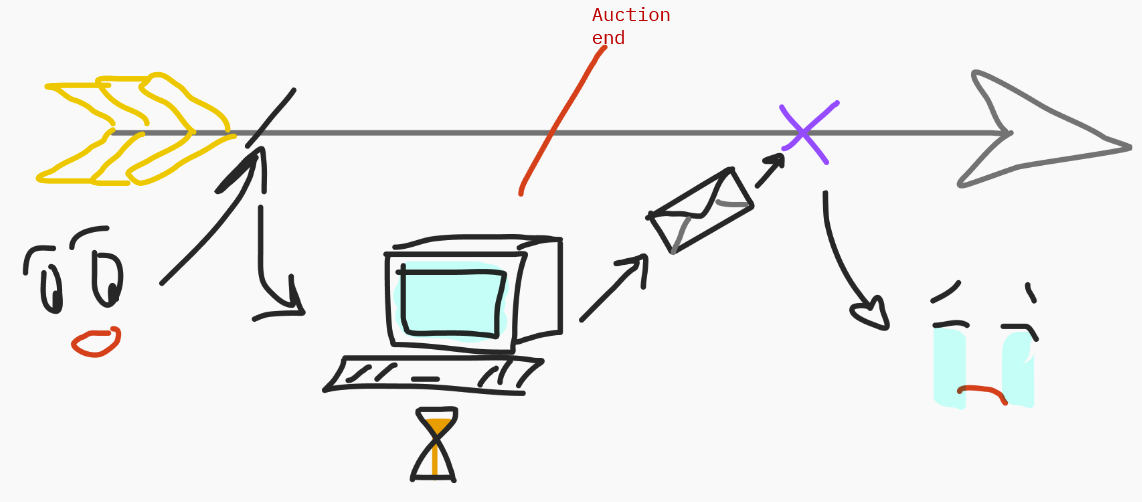
You see the auction. You want to bid, but by the time you generate your proof, the auction has ended because… let's say, it was terribly written, and it took several hours to generate the proof.
Of course, you're sad because you couldn't bid.
Or, and this is an even worse problem, maybe you saw the auction, and someone else saw it at the same time. At this point, you both see the initial state commitment of the auction contract, which is the green state below. You both craft your transaction.
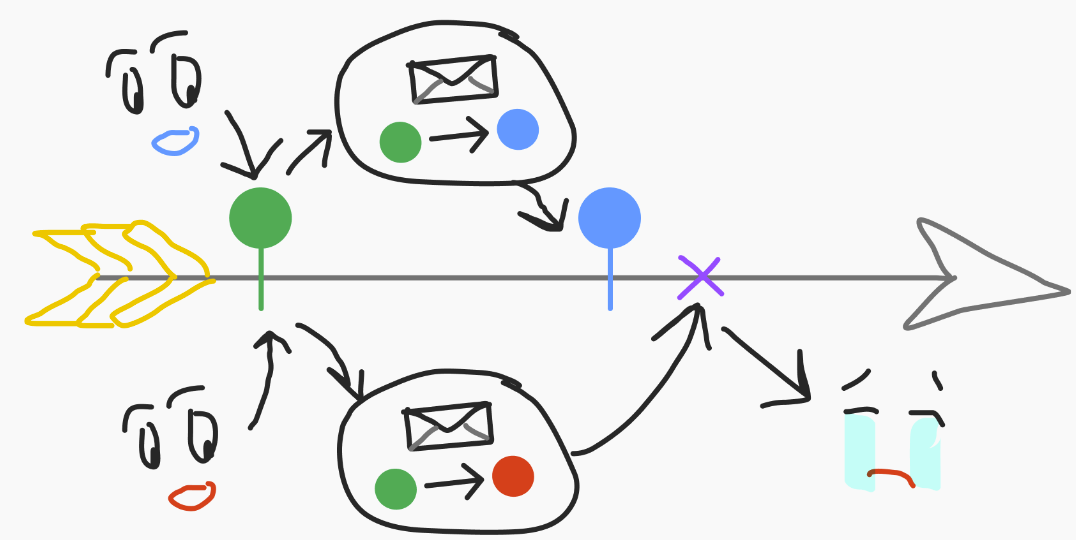
- They're both state transitions from this initial start state.
- The person on the upper timeline is faster than you because they've got a better computer or whatever. They send their transaction first, and at this point, your transaction will bounce: the proof of state transition no longer applies.
The program doesn't know if it can go from blue to red, so it rejects your transaction. Again, you are sad.
The solution: delayed proving
Thankfully, there is one solution to both of these problems, and this is what we call delayed proving.
Essentially, if you go to a restaurant, you can make a reservation, and you can claim the table when that time comes.
With delayed proving:
- Both you and the other person see the auction contract.
- You send the blob some piece of data defined by the application, the auction contract, which arrives on the chain immediately.
- You have some more time to generate proof that this transaction was indeed correct: that you have enough money to bid, or whatever the requirements are.
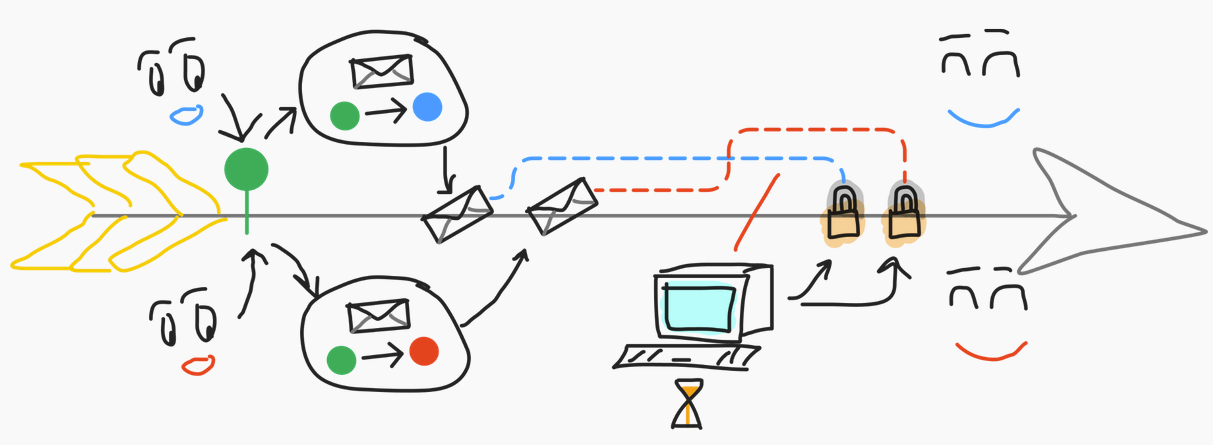
The good thing here is that once you've sent the two initial transactions, they're sequenced, so you can observe that you'll need to craft the second one, the proof based on top of the blue state, not the green state that you initially saw.
You can generate the proofs based on the correct state, and you won't have this parallelization problem. Therefore, you won't have the timeout problem because you don't need to wait for the proof to be generated to be able to send it to the chain.
You can just claim the spot and start generating the proof once you know that you're good, and while both of you won't be happy in the case of an auction, at least you'll have managed to send the chain to send the transaction to the chain and do what you wanted.
It's 2024, but you're using Hylé
If it's 2024, but you're using Hylé, you can use what we currently call « permissionless rollup mode », for lack of a better term. It means you have low latency.
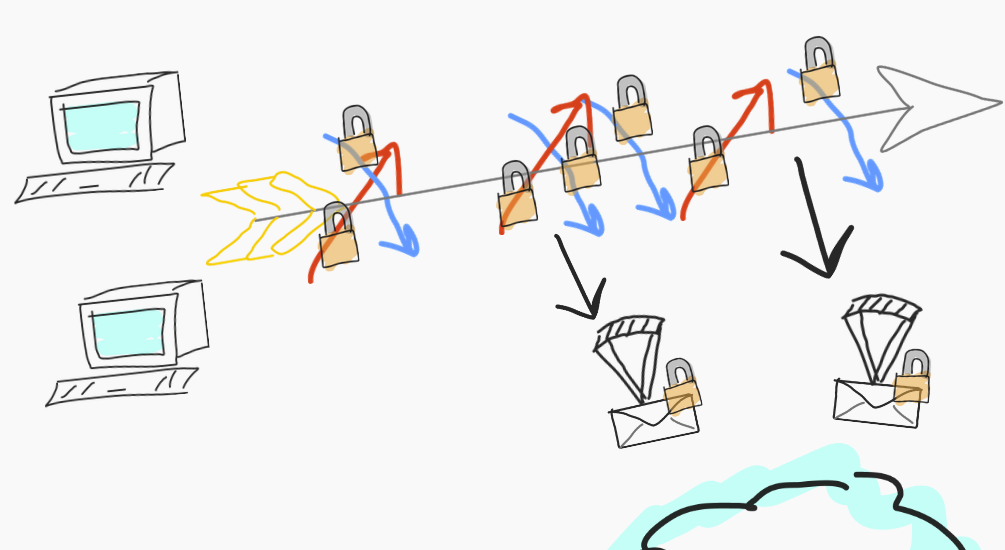
You'll want to make a p2p game. In this type of game, your players build a consensus in almost real-time − for example, the Playmint team is building towards this.
Occasionally, you want to send some side effects to a blockchain because that's where you want to tap into that liquidity. For instance, if you win a game, you should earn a reward.
You just build your consensus amongst yourselves and occasionally send that information to the chain. You have plenty of time to generate your proof, even though gaming-related proofs can be really complex. Even though it would usually be latency-dependent, here it's not because we've moved proofs out of the critical path of blockchain interaction.
This is also good because, in terms of gas costs, the chain is doing very little. We're just sequencing the information, providing a little bit of data availability because we need that, and settling by verifying your transactions. We call that a lean blockchain, seeing blockchains just as custodians of data integrity.
Thanks to zero-knowledge proofs, instead of the old world computer view, the chain is just providing sequencing, a little bit of data availability, and settlement.
Thanks to things like delayed proving and native proof composability, you have high performance and the same level of programmability that you would have on Ethereum or any other regular blockchain, except you're not interacting with half a dozen blockchains like you would if you were using different layers for all these things.
It would all happen in the same place.
Thanks for coming!