
What is a provable app?
Learn what provable apps are, how they work, how they compare to zkApps and why they are the future of a trustworthy Internet.


You may have heard of zkApps, applications that run offchain but verify their logic onchain. But did you know that they are part of a broader genre: provable apps?
In this post, we’ll explore provable apps: what they are, how they work, and, most importantly, why they can improve our online experiences.
Before reading this post, we recommend having a general understanding of zero-knowledge proofs. We wrote an introduction to zero-knowledge proofs, which you might find helpful.
What is a provable app?
In short, a provable app is any application capable of mathematically proving the validity of its changes. It’s at the core of trust infrastructure and of the future of the web.
It involves:
- a program that can prove its execution. It can be written in programming languages specifically designed for zero-knowledge proofs (Circom, Noir,Cairo…), or multi-purpose languages like Rust.
- a proof generator, which can be internal or external through a proof market or network like Gevulot.
- a proof verifier, which is external to the app. That verifier can be native, like with Hylé, or through a multipurpose virtual machine like in Ethereum.
Any application whose logic can be proved is a provable application. This means that all Solidity programs are provable thanks to zkEVMs, all Rust code is provable thanks to zkVMs, and all Cairo and Noir programs are run on provable VMs.
zkApps need to generate zero-knowledge proofs to be zkApps − if you want to know more about these, you should read this excellent thread by Will Cove. Provable apps only need to be able to generate these proofs.
That’s what makes them so unique: provable apps are based on potential. You can build a perfectly « classic » application, and if you make it compatible with zero-knowledge proof generation, then your app is provable.
If it turns out that proofs aren’t necessary, that’s fine! But if they bring privacy and security, as they usually do, or any other benefit, your app can be enhanced by this experience without having to rewrite the entire codebase.
How do provable apps work?
Let’s take the example of a social media application that relies on zero-knowledge proofs to keep post likes confidential.
If they also want censorship resistance and trustlessness, they’ll be onchain, at least partially.
If they deal with likes on a regular blockchain, they’ll go through the following process:
- They’ll push a transaction saying, « Here’s exactly what needs to be done », including every step of the transaction.
- Person A is on the list of people who are allowed to like Person B’s post
- Person A sends a like to Person B’s post
- Person B has +1 like on their post
- That blockchain’s embedded virtual machine runs the code.
- The state is updated.
The thing is, all these steps are onchain now, in clear. Anyone checking the transaction will see that the like comes from Person A. Some blockchains like Aztec or Miden enable native privacy, but all changes still have to happen onchain.
Zero-knowledge proofs allow for more privacy. In this model, I can do everything offline and only submit the proof onchain.
- Offchain, the network will say, « Person A is on the list of people who are allowed to like Person B’s post. Person A sends a like to Person B’s post. Person B has +1 like on their post. »
- They generate a proof that « Person B has +1 like on their post. »
- They verify that single proof onchain and keep the details of the transaction private.
And that’s all there is: provable apps make it easy to share the information that you want to share and keep the rest for yourself if you wish.
If we abstract this example, we get to the following flow:

If you’re comfortable with zkApps, here’s a comparison showing why zkApps are a subset of provable apps.
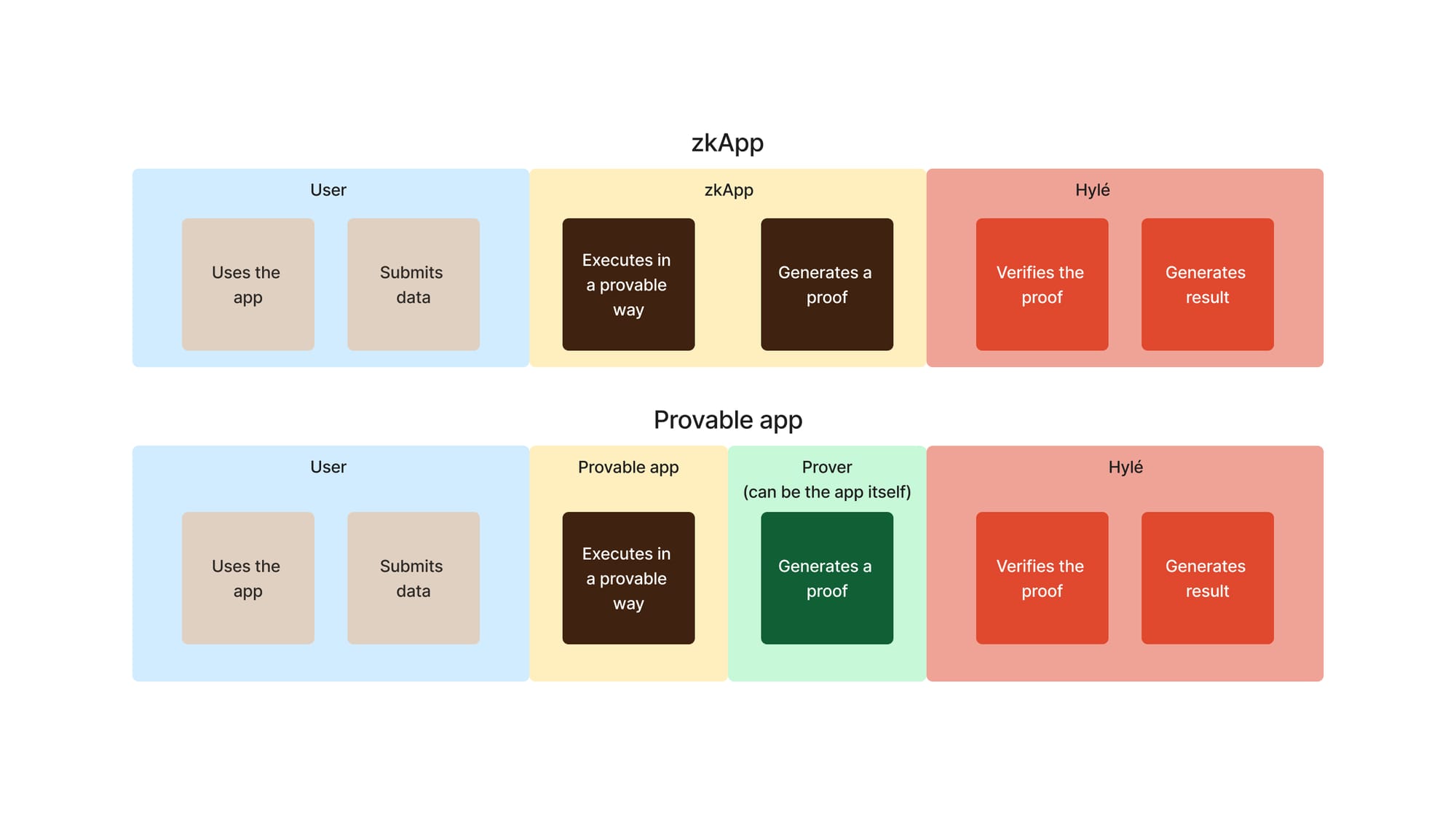
What makes provable apps so great?
Privacy
Remember our social media like, the example above? That applies to voting, too, and to a bunch of other uses where privacy is critical.
Rarimo has built solutions for secure voting based on generating a proof of passport, for instance:
In a provable app, the code can be proven by the user if the activity requires privacy (like voting does) or by a third-party prover for convenience and higher performance. Privacy is an option.
Efficiency and scalability
With a provable app, very little, if anything, needs to be onchain. You can have a completely normal Web2 app or even an offline app that will send a proof once in a while. You’re just adding a small layer on top of any app, whether it’s a software update or during the design stage.
That’s how zkRollups work, in a sense. Lots of transactions are made on the rollup. The rollup then generates proof of its state and verifies that proof on the Layer 1 it’s based on. That Layer 1 knows that the state has changed and has proof of that, but one proof could be one or a million transactions as far as it’s concerned.
In video games, this is great! Most video games involve thousands of actions per second. If you wanted them to be fully onchain, it would get really slow and expensive. But with zero-knowledge proofs, you can have checkpoints! You’ll play the game perfectly normally, offchain, and once in a while, like with a rollup, the game will batch everything you did into a single proof and verify it. This is why engines like Dojo are built with provability in mind.
Hackathon idea: @zkemail-powered "play-by-mail" game, like chess. Email the moves to your opponents, verify them onchain.
— Sylve (@sylvechv) July 19, 2024
Email is a great distribution channel. You could onboard a buttload of folks by sending them a duel request by email and using it to onboard them onchain. pic.twitter.com/ZWBDFxQu4O
Flexibility
Modularity brings flexibility. Keeping that example of a provable game, you could want to have a multiplayer online game. Currently, that is not viable on a regular blockchain for games requiring very high throughput.
But with a provable game, you could assume that your players don’t mind a centralized server as long as it is trustless. That way, you can use all the cloud computing resources available to run the best game there is and export a recurring backup to IPFS, using a zero-knowledge proof to allow people to verify that it’s the correct version of the game without having to run the whole model on their computer.
For devs, that means they can build a game without any of the constraints of zero-knowledge proofs or blockchains. They’ll just need an extra layer afterward to make the app provable, which means app design is more intuitive and has lower barriers to entry.
Reliability
A secret software change allowed FTX to use client money without ever actually telling the clients about it. That permitted Alameda Research to borrow way more money, using customers’ money as collateral than they usually could have. That’s fraud. And it’s why FTX’s crash-and-burn ending was so painful, too.
What matters in our example is that FTX lied to its clients by running code that wasn’t the code they put online and promised they were using. If FTX had been a provable app, one would have been able to generate proof that the code they were running was the code they were sharing.
FTX could also have been running fully onchain from the beginning. However, considering the difficulties of building such a system, providing proof of execution of the FTX program to end users would have been valuable and an improvement over the “just trust us” situation.
Why are apps still not all provable apps?
So, if provable apps are so great, why aren’t all apps provable?
First of all, there’s history. Web2 apps have decades of history behind them, and they’ve had no good incentive to share their information. On the contrary, protecting their data jealously has allowed them to hoard users for their walled gardens. Organizations with good intent might have considered becoming more open, decentralized, and transparent. Still, until recently, that meant refactoring their entire code base to put everything onchain, which was a hassle and less productive.
Second issue: there are still tradeoffs between privacy and efficiency. There will always be an overhead when performing provable computation. A provable app has to be able to deal with proofs, and that takes more time than dealing with nothing at all or a centralized trusted database. That said, it also takes less time than anything Web3 has done before. Counterintuitively, it’s also less complicated to run a zero-knowledge technology-based system than running fraud-proof systems that are still lagging in terms of security and auditability.
Finally, and maybe most importantly, we’ve always talked about zkApps. It’s always been about getting the developers to build the right systems. Now, provable apps allow developers to embrace existing tech without having to create everything from scratch. Prover markets are a giant step in that direction! We’ll keep infusing provability into the web in ways that don’t require changing everything about their apps.
With Hylé, things will be even more straightforward thanks to our payloads concept − which you’ll have to wait for a few more weeks to know everything about. Don’t forget to follow us if you don’t want to miss our post on that innovation!
What’s next for provable apps?
As proving technology and tools advance, developers of non-provable apps won't need to rewrite their entire codebase. Everything will become provable because zkVMs will eventually prove any programming language.
Currently, the only option for Web2 projects was to « trash everything you’ve done up until now and rewrite it in Solidity ». Your banking software is still written in Cobol. Nobody’s going to rewrite it. But if there’s a Cobol zk-proof generator somewhere, then maybe your bank account can become provable. Then, all of a sudden, banks are on the blockchain.
Provable apps will gradually onboard legacy systems to Web3, adding security without massive switching costs. In the next generation of the Internet, instead of forcing Web2 to conform to Web3, we'll lower the entry barrier for Web3, eventually making it indistinguishable from Web2.
Some industries with highly private information, like finance and healthcare, will highly benefit from zero-knowledge proofs. If they start using it, other industries will follow because building provable apps has no extra cost and a bunch of benefits. People will start expecting apps to be provable, and being closed and untrustworthy will become a real problem for developers.
This will raise people’s expectations of how an application should run and what guarantees it should offer. In a few years, it will sound ridiculous that it was impossible to know if the data a website serves actually comes from a trustworthy source, the same way it sounds ridiculous not to use HTTPS today.
We want a world where being trustworthy is easy and necessary. That’s why we’re building Hylé, the lean blockchain for your provable applications.