
Proof verification needs to change


Zero-knowledge proofs are the future of blockchain. They enable great blockchain scalability while remaining trustless. But we're using them wrong. Today, onchain proof verification is really expensive and inefficient. It doesn't need to be that way.
How verification works
Let’s review how zero-knowledge proofs currently work.

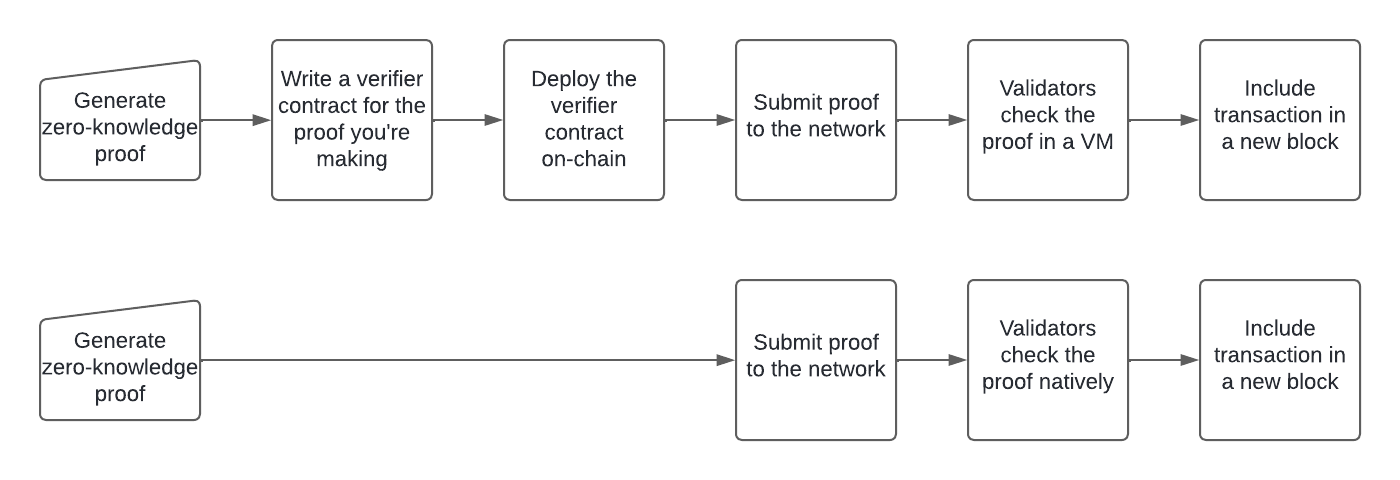
- Write a verifier contract, which is usually unique to the particular thing you’re proving, then deploy the verifier smart contract on-chain. The contract needs to be audited, and because the contract is specific to your app, if you change anything on the app, you need to redo this entire step.
- Proof generation: Off-chain, the prover generates a zero-knowledge proof of a specific computation.
- Proof submission: the prover sends the proof and the computation results to the blockchain network.
- Verification: validators receive the transaction. They use complex cryptographic algorithms in a virtual machine to check the validity of the proof.
- Consensus and block inclusion: if the proof is valid (the verification is successful), the block producer includes the transaction in a new block, making it permanent on-chain.
There is no native method for verifying zero-knowledge proofs in classic blockchain networks.
Because of this lack of compatibility, verifiers create programs to make it able to run on the blockchain’s virtual machine. This means that for every single verification, they boot up a virtual computer that could run any program, and then make it run this specific verification program.
As you can imagine, the way this is designed today bloats the whole process of deploying, upgrading, and running a ZKP-based application, no matter how complex the computation is, and can have extremely high costs for more complex protocols.
All this can get quite expensive: zk-rollups pay $15-500 in gas fees to verify a single proof on Ethereum.
TIL Worldcoin pays $2-3M/month just to verify proofs on ETH L1https://t.co/9pByT76y5Y
— Dmitriy Berenzon (@dberenzon) March 8, 2024
and if you wanted to include a proof in every block, you'd be paying ~$200M/year in gas fees
h/t @garvitgoel03
Aggregation for scalability
Instead of verifying each zero-knowledge proof one by one, there is a push to aggregate them.
Say you have 100 transactions to make. With the help of a proof aggregator, you can ask their rollup to demonstrate the validity of ten proofs and generate a proof for that. This way, instead of 100 proofs, 10 proofs that are actually batches of 10 proofs themselves will need to be verified.
Aggregation is recursive: you can take these 10 batch proofs and aggregate them into another proof. Now, instead of 100 proofs, you only have one proof to verify on-chain. You’ve divided your costs by 100.
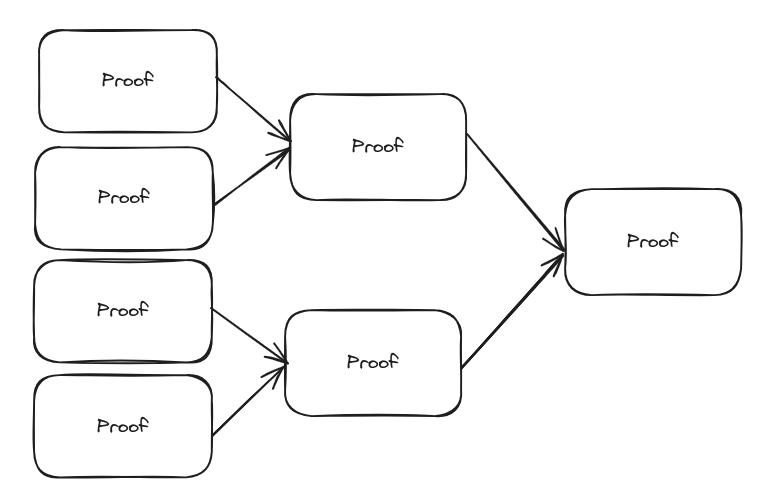
This aggregation is a trusted way of bringing verification costs down.
There is a tradeoff, though: it takes a lot of time to generate all these new proofs. Every aggregation step means the whole proving process has to start again.
More critically, you need to wait to accumulate enough proofs for aggregation to be profitable, meaning that aggregation is only relevant if you’re ready to wait for a while or if you create many proofs at once.
Finally, proofs can't be aggregated if they don't have the same proving system, at least in the current state of things.
Aggregation is good, but it doesn’t solve the core issue: proof verification should be a native feature of blockchains.
The future is built with native proof verification
Remember when we highlighted the issues of an embedded virtual machine at the beginning of this post?
Remember this part, especially?
There is no specific block type or smart contract for verifying zero-knowledge proofs in classic blockchain networks.
Well, that can be solved with native proof verification.
Zero-knowledge proof allows us to verify information without re-executing it if we’re not using a virtual machine. If it’s native in a block, then it will require much lower computing resources.
Modularity allows you to choose your favorite execution layer and your own state storage solution. With native proof verification, you can take all that wherever you’d like and only use blockchain for what matters: confirming that the information is true.
The main value of this is simplicity. Once we’ve reduced the chain's feature set, native proof verification has no execution, lighter nodes, and fast finality, allowing for easy storage, maintenance, and peer-to-peer communication. Most importantly, it’s future-proof.
To achieve all that, though, we must break everything down and take execution entirely off-chain. We must build a new system that only relies on zero-knowledge proof and state diffs.
And that’s where Hylé comes in.
Native proof verification on Hylé
Hylé wants to make proof verification native, creating a minimal Layer 1 designed for proof verification.
Using Hylé’s sovereign verification-focused Layer 1, here’s what happens:
- There is no need for a verifier contract: just call the native function.
- Proof generation: This doesn’t change. Off-chain, the prover generates a zero-knowledge proof of a specific computation.
- Proof submission: the prover sends the proof and the computation results to Hylé’s Layer 1 as part of a transaction.
- Verification: Hylé validators receive the transaction. They use native verification programs to check the validity of the proof as fast as possible, without being limited by the bulky virtual machine.
- Consensus and block inclusion: if the proof is valid, the block producer puts the computation results on the Hylé blockchain.
Side by side, here are the process above and the Hylé process, with changes highlighted in orange:
And that’s it.
With this system, execution and storage happen anywhere you like, without cost barriers. You only need a fast and trustworthy verifier: Hylé, the minimal Layer 1 focusing on proof verification.