
All rollups are apps, all apps are rollups

At DevCon 2024’s ZK Accelerate, Sylve spoke about how all rollups are apps, all apps are rollups. You can watch the video or read the highlights below!
All apps are rollups
Creating an onchain game
It’s 2030, and you want to build an onchain game.
You want low latency. You don’t want to think about block data or gas limits since block space isn’t an issue anymore in 2030. You’re gating the access to your game with an NFT, or you want your game to be super-private, with your friends never finding out that you’re attacking their ships, so you’ll use ZK.
To deal with all of this, you prefer to execute offchain and verify your proofs onchain.
Doesn’t that sound like a rollup?
What’s a rollup?
Let’s take a second to remember what a rollup is. With a rollup, you have:
- a state commitment on the base layer,
- everything else in the L2 because the main chain doesn’t need it, thanks to validity proofs.
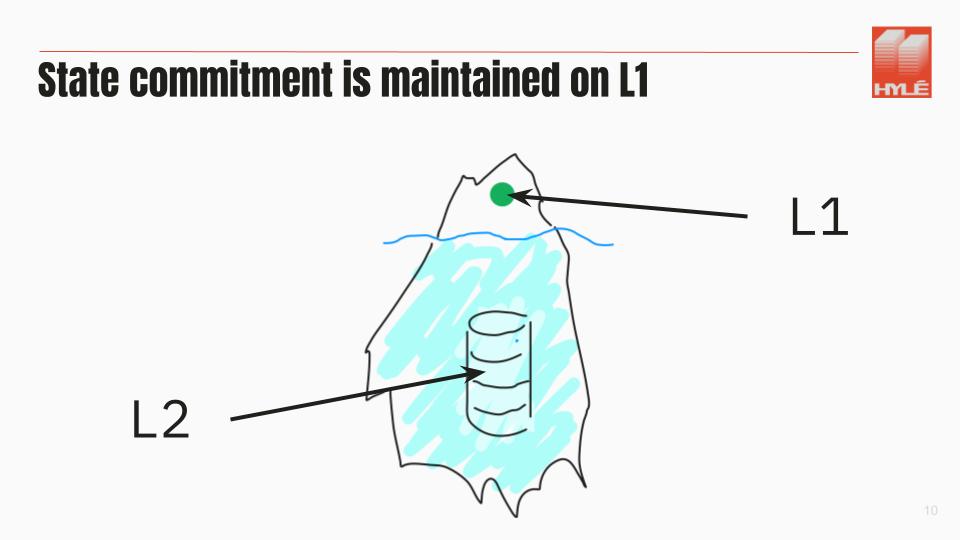
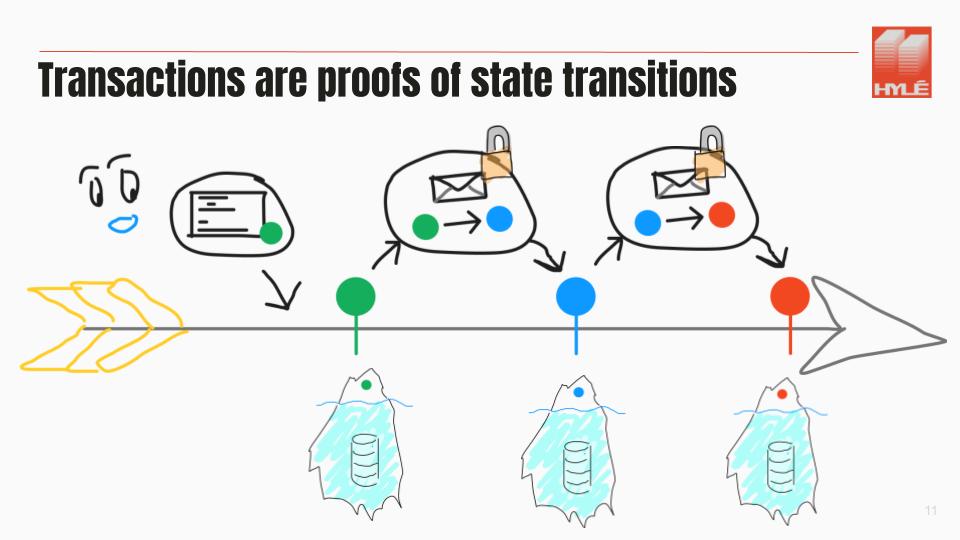
You don’t need to execute everything on all the computers at the same time: you can only verify proofs of state transitions, summarizing what happened on the rollup.
The only thing that a blockchain needs to verify is the state transition.
And how do you generate these proofs? You have several options:
- You send the information to the game, the game generates the proof, and you send the proof to the blockchain,
- You send the information to a proving market or network, which generates the proof and sends it to the blockchain,
- You create your proof client-side and send it to the chain yourself for full privacy.
Whatever you choose, accessing onchain data is the same. Either you talk directly to the chain, or an indexer is linking the chain and the dApp, and you talk to the application.
One problem that isn’t solved by any of these, though, is bridges. With the current system, every application is an island, and they’re not interoperable. A contract that lives on rollup A can’t talk with a contract on rollup B.
Let’s recap:
- In 2030, transactions are proofs of state transitions.
- Your applications are just a verification key and a state root; everything else is irrelevant to the settlement layer.
Proof composability: a new standard
Let’s come back to 2024.
Today, you may want to adopt the same approach for your provable application. But you’ll encounter several roadblocks if you do that:
- Difficulty in composing contract calls;
- Long proving time & high latency;
- Lack of parallelization.
Composable contract calls
It’s challenging to compose smart contract calls if everything lives on different rollups. It’s very easy, on the other hand, if everyone is on the same computer.
Everyone wanting to be on the same blockchain is basically everyone wishing to be on the same computer: it’s great for usability, but there’s only so much RAM & CPU space that you can use, and performance will suffer.
Fortunately, we have an answer for composable contract calls.
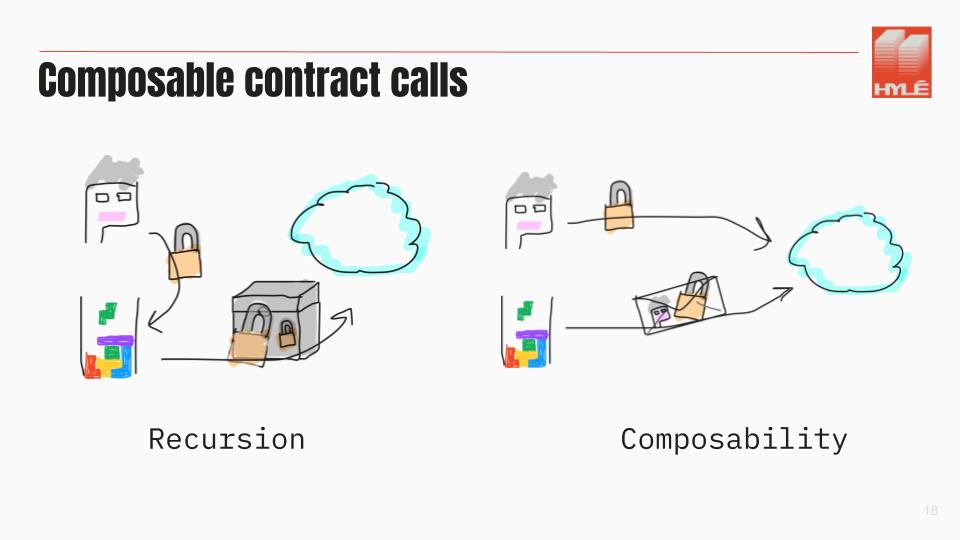
Let’s say that you have two proofs:
- zkEmail,
- Risc0.
Your application requires both of them: the zkEmail proof asserts the player’s identity and the Risc0 proof allows you to prove that the player won their game. In the case of our grantee Matteo, he had a Rust library for chess and proved victory using Risc0.
The current solution is recursion: you prove zkEmail inside Risc0 or Risc0 inside zkEmail. If you change anything in one of these contracts, the whole app collapses.
Proof composability should be the standard.
With proof composability, you have a zkEmail proof that is valid and a Risc0 proof that is valid. The zkEmail proof can say, « I am only valid if the Risc0 proof is valid ». It doesn’t need to verify the Risc0 proof; it only needs to be conditioned by it.
When you send both proofs onchain, they’re verified atomically at the same time. When you compose proofs, you don’t need recursion; you only need an if.
Proving time and parallelization
If you’re bidding at an auction, you don’t want the auction to end while your proof of bid is being generated. You also don’t want someone to bid right after you, but because of their superior hardware, they can generate a proof faster.
We avoid this by taking proofs out of the critical path.
There are some solutions to this kind of issue, especially around parallelization. Mina, for instance, solves this by requiring everything to be sequenced at the application level. But we want things to be decentralized and trustless, so instead, we rely on pipelined proving.
Lancelot talked about pipelined proving in this previous talk:

If you prefer a written format, our tech team also wrote a blog post about it:

Hylé and proof composability
As you hopefully know if you’re reading our blog, Hylé is a decentralized Layer 1 blockchain optimized for provable applications. Think of it as a blockchain that doesn’t handle execution: it’s up to the application developer to decide which execution environment they want.
Whether you want something that is fully decentralized with different sequencers or something fully client-side, we’ve got you! Hylé sequences the provable transactions and handles state transactions through validity proofs.
Of course, we offer proof composability and pipelined proving. This way, Hylé recreates the abstraction of a « world computer »: rather than having bridges, everything is a provable smart contract. We see this as the future of decentralized blockchains in a post-ZK world.
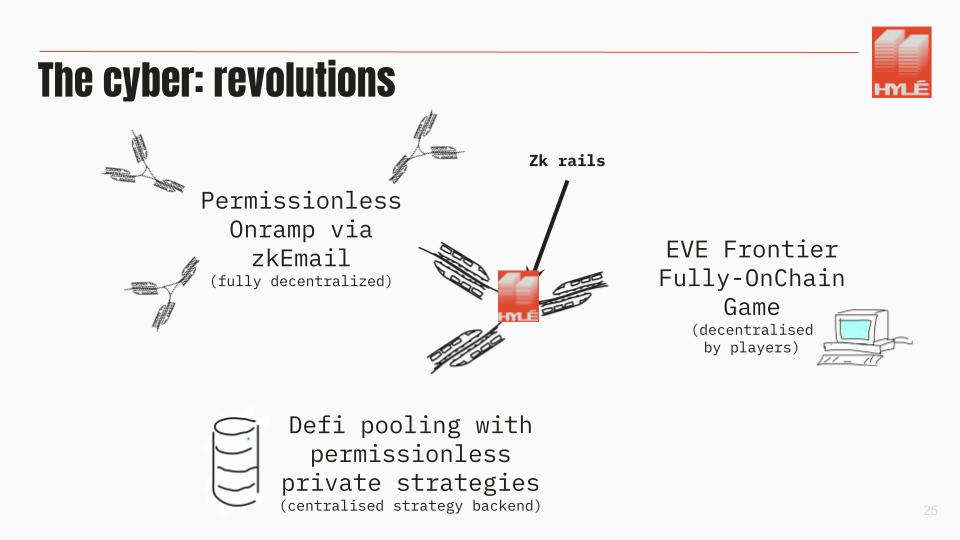
If ZK is a railway, then Hylé is the train station connecting all the lines. In this example, we’ve included:
- a permissionless onramp via zkEmail, like zkP2P, which is fully decentralized and proved client-side
- DeFi pooling with permissionless private strategies, with a centralized backend and validity proofs that allow it to remain manageable and trustless
- a fully onchain game running on everyone’s computers
We give you any shade of decentralization you want because you can do whatever you wish in the execution stage. And thanks to validity proofs, we guarantee data integrity, trustlessness, and composability.
Questions from the audience
Issues with recursion
You mentioned that the whole tower of proofs will collapse if one of the proofs doesn’t work. Wouldn’t it be easier to verify each proof natively and then put recursion?
There are many issues with recursion. François Garillot says it very eloquently: the gold standard for proof verification on Ethereum right now is 300k gas.
9/
— Foxi 🦊 (DeFi / AI) (@Foxi_xyz) September 1, 2023
4️⃣ Relaying Proofs
General proof verification on the EVM costs 600k gas, so SNARKs solution is used
Herodotus optimizes proofs by batching state updates and proving relevant Merkle tree batches for specific data items (like rollup). pic.twitter.com/GonG0te1JI
What that means is:
- we have top-notch proving schemes available, but…
- they need to be recursed into a groth16 proof to comply with the 300k gas limit.
That adds a lot of overhead: latency and the need for aggregation. Aggregation is excellent in itself, but it means you need to wait until there are enough proofs to verify.
That’s what makes verifying natively and using proof composition worth it.
Data availability
Can you tell us what’s the design of the DA?
Where we’re going, we don’t need execution. All we need is to sequence the transactions. But in order to generate the proof for the state transition, you do need to access the data; otherwise, you won’t be able to generate the proof. That’s where DA comes from.
In our case, we don’t need to hold that data for very long. With pipelined proving, you can send your transaction, and it will stay on the DA layer of Hylé. But we’ll enforce timeouts: once your transaction is sequenced, you won’t have weeks to send your proof. This means that our client can be very lean. We may use data availability sampling in the future, but in the beginning, it’s not much of a concern for Hylé.
Avoiding double-spending issues
With this architecture, how do you avoid double spending?
Let’s take an auction as an example: two people place a $10 bid at different times. Hylé does not guarantee the validity of the transactions.
In order to settle all these transactions, the prover needs to generate a proof. That proof is a correct state transition from A to B. If you’re creating a double spend, you’ll need to execute the transaction and prove it. But because of how we’ve ordered incoming transactions, the original state will have changed by the time your proof is verified, and verification will fail.
It’s not necessarily intuitive because the DA layer does not tell you anything about the validity of the transactions before the proofs are settled. You work under the assumption that you know the proof will be verified; Hylé is more of a storage layer at that point.
An app that would have been hard to build without Hylé
Do you have an example of an app that exists and would have been much harder to build without Hylé?
Yes! Our first grantee, Matteo, created a provable play-by-email game engine. You can read more about this in our case study:
