
A simple introduction to zero-knowledge proofs (ZKP)
A simple introduction to zero-knowledge proofs and zk-rollups, that requires no previous understanding of cryptography or blockchain at all.


In this post, we’ll learn how zero-knowledge proofs work and why they’re the future of blockchain.
Most explanations of zero-knowledge proofs are geared toward people who already know a lot about computer science and cryptography. We’ve decided to take one step back and really take it from the beginning. Part 1 of this post explains the concept of zero-knowledge proofs, which requires no specific previous knowledge. Part 2 is about how zero-knowledge integrates with the blockchain. A basic understanding of blockchain and rollups can help, but it is not necessary either.
Let’s dive in!
What is a zero-knowledge proof?
A zero-knowledge proof (usually abbreviated as zk-proof or ZKP) is a cryptographic method to prove that a piece of information is true without revealing the information itself.
A brief history of zero-knowledge proofs
Zero-knowledge proofs were born in 1985, when Shafi Goldwasser, Silvio Micali, and Charles Rackoff published a paper called « The Knowledge Complexity of Interactive Proof-Systems ».
In 1991, the same Silvio Micali, Oded Goldreich, and Avi Wigderson published another paper. « Proofs that yield nothing but their validity or all languages in NP have zero-knowledge proofs » showed that zero-knowledge proofs could have many real-world uses.
Until very recently, however, ZKP was only a nice theory. The real-life applications would be great, sure… but the computation involved was way too complex to be viable.
In recent years, advances in cryptography and computing power have turned zero-knowledge proofs into a much more usable tool.
How zero-knowledge proofs work
Où est Charlie − probably known to most readers as Where’s Waldo − is a common example of zero-knowledge proof. (Image taken from the excellent ZK-WALDO intro.)
If you’ve already seen this example a hundred times, instead of asking Where’s Waldo, ask yourself, How’s Waldo?. Also, skip this section. We won’t hold it against you.

I can show you this image and tell you I’ve found Waldo. But how can I prove that’s true without showing you where he is?
In this context, I’m the prover, and you’re the verifier.
I can choose to only show you Waldo's face without surrounding context to prove that I've found Waldo without showing you where he is.
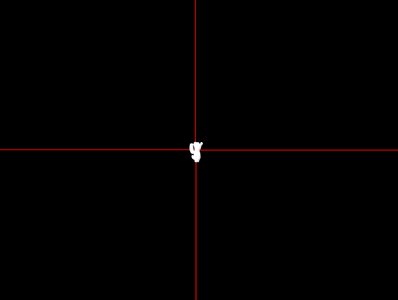
Waldo could be anywhere, from the bottom left to the upper right corner of the image. But with this format, the cutout is always going to be smack in the middle.
Wherever Waldo is, he always appears at the center of the black screen for the verifier.
This way, you know I’ve found him, but it doesn’t help you find him in the image − you can still play!
This is what happened in this scenario:
- I do my computation (i.e., I find Waldo in the image)
- Being the prover, I create a zero-knowledge proof (a cutout that only shows him and not his environment)
- I show my proof to the verifier (that’s you!)
- You do your computation: you look at the cutout and confirm that this is, indeed, Waldo.
- Since I showed you a cutout of only Waldo’s face on the page, you have verified that I have found Waldo. Congrats!
Of course, zero-knowledge proof requires much more computation. It involves very complex cryptographic protocols and a long series of calculations.
The information is also often checked more than once. In a slightly more complex zero-knowledge proof example, you can prove that you've completed a sudoku grid without ever showing how you did it. That example includes this multiple check. On his blog, Lauri Peltonen wrote a very clear no-math explanation of the sudoku example, which we recommend reading.
When are zero-knowledge proofs useful?
The three classic situations
Here are three situations for which zk-proofs are perfectly suited and an example of how each can be applied.
| Concept | Computing power imbalance ZKP allows you to make sure that a computation has been executed correctly without re-doing it. It’s especially useful if you have limited computation power. | Integrity ZKP allows you to share the results of your computations without having to reveal how you arrived at them. Sharing only the result also means you can execute your computation wherever it consumes the fewest resources. | Anonymity With ZKP, you can prove one specific piece of information without having to disclose anything else. |
| Example | Machine learning Modern machine learning, like LLMs, is very resource-intensive, so you probably can’t run the entire computation onchain to make sure the model and inputs are what the model owner says they are. The field of zkML solves this by proving that the announced parameters are true without having you re-do the whole process. | Protecting your secret recipe If you’re a chocolate cookie maker and you have the best recipe in the world, you might want to prove that you have that recipe without actually disclosing it.Veridise shows this example in detail on their blog. | Authentication You can prove something about yourself without revealing your full identity. Zupass allows you, among many other use cases, to prove that you attended an event without showing who you are. |
We’ll be discussing use cases for zero-knowledge technology extensively on this blog, so stay tuned!
How do zero-knowledge proofs integrate with blockchain?
SNARK, STARK, and the others
There are many types of zk-proofs, and you may hear about SNARKs and STARKs relatively often. Without going through the whole list, let’s just define these two. This section of the blog post is heavily inspired by Chainlink’s blog post « Understanding the Difference Between zk-SNARKs and zk-STARKS »: check it out for a more detailed explanation.
zk-SNARKs (Zero-Knowledge Succinct Non-interactive Argument of Knowledge) were invented in 2012 by Nir Bitansky, Ran Canetti, Alessandro Chiesa, and Eran Tromer. In short, they create a proof that can’t be falsified: a SNARK is secure if it is impossible to create a convincing proof of a false statement. Unfortunately, you need a trusted setup to verify their proofs, which can deter some users who want full trustlessness. Vitalik made a good blog post on what trusted setups are and where they’re going if you want to dive deeper.
Six years later, Eli Ben-Sasson, Iddo Bentov, Yinon Horesh, and Michael Riabzev invented zk-STARKs (Zero-Knowledge Scalable Transparent Argument of Knowledge). The method does not require a trusted setup but is slower and more data-heavy than zk-SNARKs.
STARKs don't require a trusted setup, but they haven't taken over the entire industry. zk-SNARKs are faster and have six more years of existence under their belt, and switching isn't easy! That's why both types of zero-knowledge proofs, and many more less-famous ones like Bulletproofs, exist alongside each other in the crypto world. Each solution solves a specific problem, and there is no one-size-fits-all.
zkApps
zkApps are decentralized apps that rely on zero-knowledge proofs to run, ensuring privacy and security. They belong to the bigger genre of provable apps.
Why ZK rollups improve on optimistic rollups
In this section, we assume you know what a rollup is in crypto. If not, here’s a short definition. A rollup is a protocol that processes and executes transactions outside of the main chain (also known as Layer 1) and then uploads a batch of results to the main chain. Think of it as taking the train rather than the car: it’s cheaper, faster, and you can fit way more people into a single wagon.
Optimistic rollups assume that all transactions are valid. They’re very fast and scalable, but they also have a margin of error. Because of this, they include a dispute window of several days.
If a validator believes a transaction is not valid, they create a dispute. The rollup then recomputes everything in that batch and verifies the results to cancel fraudulent transactions. You must have sufficient incentives and time for someone to find an error and flag it. This is why finality (the moment we agree that a transaction has happened) is slow in optimistic rollups.
Zero-knowledge rollups, on the other hand, generate a cryptographic proof for every single batch of transactions. This makes them harder to create since the computation is done every time.
It also means that once the computation is done, there can be no proof or cancellation; there is instant finality. Because the proof is automatically generated using complex math and not verified by validators who have a financial incentive to act in good faith, it is also more secure.
Zero-knowledge rollups are better than optimistic rollups. However, until solutions like proof aggregation and Hylé’s specialized sequencing and settlement layer existed, they were also much harder to set up, meaning that optimistic rollups still lead the market. For now…
The process for zero-knowledge proofs onchain
Let’s review how zero-knowledge proofs currently work.

- Write a verifier contract, which is usually unique to the particular thing you’re proving, then deploy the verifier smart contract onchain. The contract needs to be audited, and because the contract is specific to your app, if you change anything on the app, you need to redo the entire thing.
- Proof generation: Off-chain, the prover generates a zero-knowledge proof of a specific computation.
- Proof submission: the prover sends the proof and the computation results to the blockchain network.
- Verification: validators receive the transaction. They use complex cryptographic algorithms in a virtual machine to check the validity of the proof.
- Consensus and block inclusion: if the proof is valid (the verification is successful), the block producer includes the transaction in a new block, making it permanent onchain.
Is this efficient?
In short, it’s good, but zero-knowledge proofs are highly limited by the blockchain networks on which they are stored. Right now, people need to use a virtual machine to check the validity of the proof onchain, which means the process can be very slow and cumbersome. We at Hylé believe that a better approach is to make zero-knowledge proof verification native. And that’s what we’re working on!
But that’s taking things a bit further than an introduction needs to go − so let’s leave it at that for today.
We want to help everyone understand zero-knowledge proofs regardless of their level of expertise. If you have any questions or if anything in this blog post is unclear, please reach out to us, and we’ll see how we can improve it!